Both the SPSS datasets we have been working with so far have contained different information about the English Housing Survey (EHS). We will join these together to create a single analysis dataset with all the information we need.
First we need to reload the tidy datasets we saved previously (now using the read_csv function):
Rows: 9752 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): tenure_type, region
dbl (2): id, weighting
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 9752 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): length_residence, freehold_leasehold
dbl (4): id, gross_income, weekly_rent, weekly_mortgage
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Notice that by default, the variables that were classed as factors have been recognised by R as chr (character). This is because CSV files are unable to store the grouping attributes that were created in R. Therefore, when we load in CSV files, we need to use the mutate function to re-classify these variables.
When we need to apply the same function to a group of variables within a dataset, the mutate function can be combined with across, which uses selection helpers (see ?dplyr_tidy_select) and retains the original variable names
When writing script files, we want our code to be as concise and efficient as possible. Although we could use mutate to apply the factor function to each of the categorical variables, using the wrapper across reduces the amount of code needed and, consequently, the risk of errors.
Joining datasets can be carried out using join functions. There are 4 options we can choose from depending on which observations we want to keep if not all of them are matched (see ?full_join for a full list of options).
In this example, we want to keep all observations, even if they are missing from one of the datasets. This requires the full_join function. Both datasets contain a unique identifier which can be included in the full_join function to ensure we are joining like-for-like:
# A tibble: 6 × 9
id weighting tenure_type region gross_income length_residence weekly_rent
<dbl> <dbl> <fct> <fct> <dbl> <fct> <dbl>
1 2.02e10 3934. owner occu… East 38378. 20-29 years NA
2 2.02e10 1580. owner occu… South… 26525 30+ years NA
3 2.02e10 3360. owner occu… West … 25272. 10-19 years NA
4 2.02e10 1368. owner occu… East … 51280. 3-4 years NA
5 2.02e10 9847. owner occu… South… 14365 30+ years NA
6 2.02e10 3262. owner occu… West … 38955 30+ years NA
# ℹ 2 more variables: weekly_mortgage <dbl>, freehold_leasehold <fct>
5.2 Summarising data
Summary tables can be created using the summarise function. This returns tables in a tibble format, meaning they can easily be customised and exported as CSV files (using the write_csv function).
The summarise function is set up similarly to the mutate function: summaries are listed and given variable names, separated by a comma. The difference between these functions is that summarise collapses the tibble into a single summary, and the new variables must be created using a summary function.
Common examples of summary functions include:
mean: a measure of centre when data are normally distributed
median: a measure of centre, whatever the distribution
range: the minimum and maximum values
min: minimum
max: maximum
IQR: interquartile range, gives the range of the middle 50% of the sample
sd: standard deviation, a measure of the spread when data are normally distributed
sum
n: the number of rows the summary is calculated from
For example, if we want to generate summaries of the gross household income using the entire dataset:
The summarise function can be used to produce grouped summaries. This is done by first grouping the data with the group_by function.
Warning
Whenever using group_by, make sure to ungroup the data before proceeding. The grouping structure can be large and slow analysis, or may interact with other functions to produce unexpected results.
For example, we can expand the gross income summary table to show these summaries separated by region:
# A tibble: 9 × 4
region total_income median_income n_rows
<fct> <dbl> <dbl> <int>
1 East 55188890. 37225 1275
2 East Midlands 31706518. 32453 806
3 London 59369895. 42278. 1199
4 North East 15381138. 26324. 474
5 North West 51011810. 29642 1410
6 South East 72646076. 39087. 1600
7 South West 44236539. 34958. 1105
8 West Midlands 32522051. 30984. 878
9 Yorkshire and the Humber 35681216. 29900 1005
Before creating summary tables, it is important to consider the most appropriate choice of summary statistics for your data.
5.2.1 Summarising categorical data
To summarise a single categorical variable, we simply need to quantify the distribution of observations lying in each group. The simplest way to do this is to count the number of observations that lie in each group. However, a simple count can be difficult to interpret without proper context. Often, we wish to present these counts relative to the total sample that they are taken from.
The proportion of observations in a given group is estimated as the number in the group divided by the total sample size. This gives a value between 0 and 1. Multiplying the proportion by 100 will give the percentage in each group, taking the value between 0 and 100%.
For example, to calculate the proportion of respondents that live in privately rented properties, we divide the total number in that group by the total number of respondents:
ehs_tidy %>%# First group the data by tenure typegroup_by(tenure_type) %>%# Then count the number of rows in each of these group (types)summarise(n_tenancy =n()) %>%# Be sure to ungroup to remove this structure!ungroup() %>%# Now calculate the total number of respondents overall mutate(n_responses =sum(n_tenancy),# and divide the group total by the overall totalprop_tenure = n_tenancy / n_responses)
From this summary table, the proportion of responders that lived in privately rented properties was 0.178. To convert this into a percentage, we multiple the proportions by 100%:
ehs_tidy %>%# First group the data by tenure typegroup_by(tenure_type) %>%# Then count the number of rows in each of these group (types)summarise(n_tenancy =n()) %>%# Be sure to ungroup to remove this structure!ungroup() %>%# Now calculate the total number of respondents overall mutate(n_responses =sum(n_tenancy),# and divide the group total by the overall totalprop_tenure = n_tenancy / n_responses,perc_tenure = prop_tenure *100)
Therefore, 17.8% of responders lived in privately rented properties.
5.2.2 Summarising numeric variables
Numeric variables are typically summarised using the centre of the variable, also known as the average, and a measure of the spread of the variable. The most appropriate choice of summary statistics will depend on the distribution of the variable. More specifically, whether the numeric variable is normally distributed or not. The shape/distribution of a variable is typically investigated by plotting data in a histogram.
Measures of centre
The average of a numeric variable is another way of saying the centre of its distribution. Often, people will think of the mean when trying to calculate an average, however this may not always be the case.
When data are normally distributed, the mean is the central peak of the distribution. This is calculated by adding together all numbers in the sample and dividing it by the sample size.
However, when the sample is not normally distributed and the peak does not lie in the middle, extreme values or a longer tail will pull the mean towards it. Where data are not normally distributed, the mean will not be the centre and the value will be invalid. When this is the case, the median should be used instead. The median is calculated by ordering the numeric values from smallest to largest and selecting the middle value.
When data are normally distributed, the mean and median will give the same, or very similar, values. This is because both are measuring the centre. However, when the data are skewed, the mean and median will differ. We prefer to use the mean where possible as it is the more powerful measure. This means that it uses more of the data than the median and is therefore more sensitive to changes in the sample.
Measures of spread
Generally the measure of the spread of a numeric variable is presented with a measure of spread, or how wide/narrow the distribution is. As with the apread, the most appropriate values will depend on whether the sample is normally distributed or not.
The most simple measure of spread is the range of a sample. In R, this is given as two values: the minimum and the maximum.
The issue with using the range is that it is entirely defined by the most extreme values in the sample and does not give any information about the rest of it. An alternative to this would be to give the range of the middle 50%, also known as the interquartile range (IQR).
The IQR is the difference between the 75th percentile, or upper quartile, and the 25th percentile, or lower quartile. As with the median, this is calculated by ordering the sample from smallest to largest. The sample is then cut into 4 and the quartiles are calculated. In R, the IQR is given as the difference between the upper and lower quartiles. To calculate these values separately, we can use the quantile function.
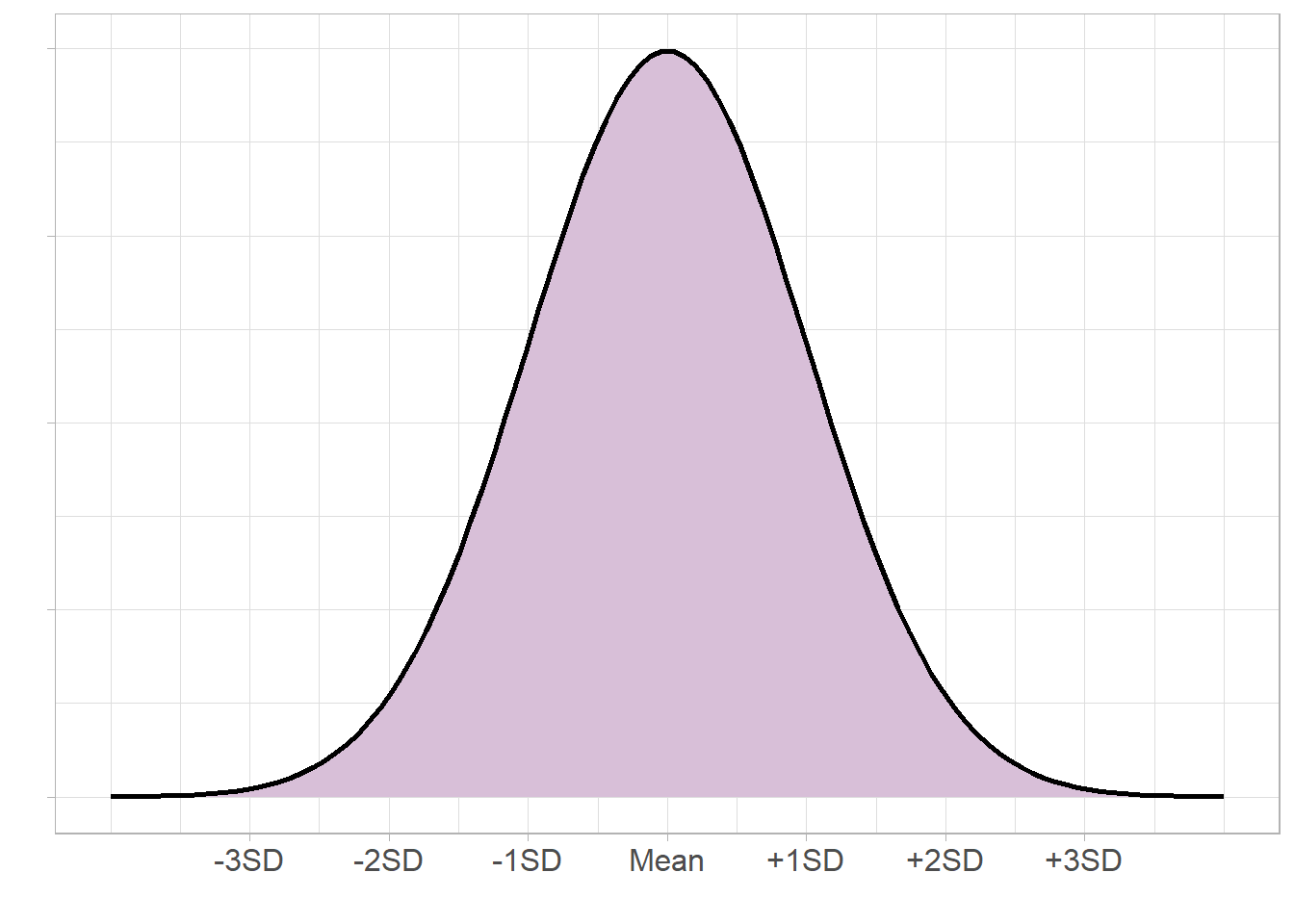
Both the range and IQR only use 2 values from the sample. As with the median, these measures discard a lot of information from the summaries. Where the sample is normally distributed, the standard deviation (SD) can be used which measures the average distance between each observation and the mean. The larger the SD, the wider and flatter the normal curve will be; the smaller the SD, the narrower and taller the curve will be:
The standard deviation is only appropriate where a numeric variable has a normal distribution, otherwise this value is meaningless.
Properties of the normal distribution
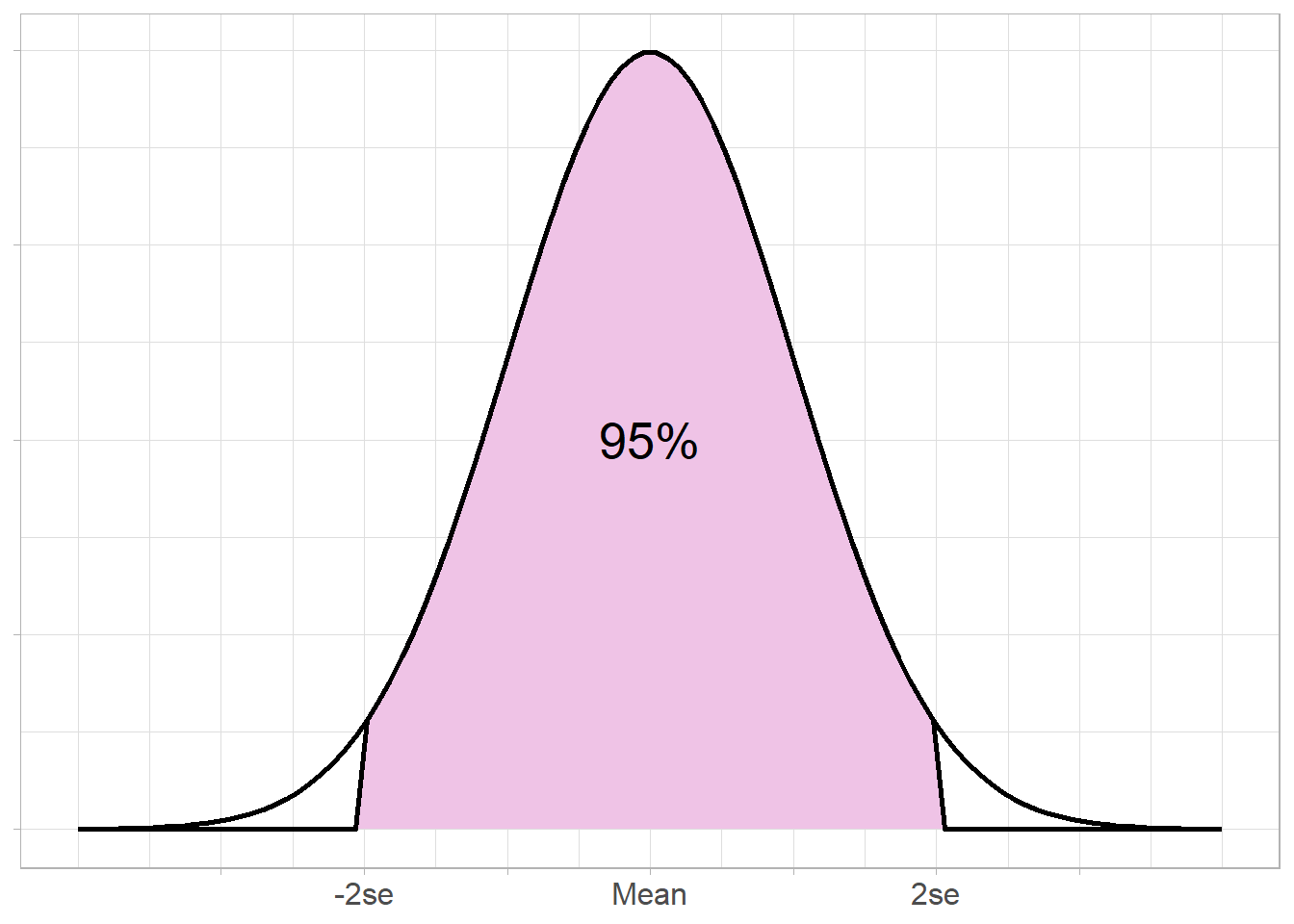
If a sample is normally distributed, then it can be completely described using the mean and standard deviation, even when the sample values are not given. As the distribution is symmetrical, the mean and standard deviation can be used to estimate ranges of values.
For example, it is known that approximately 68% of a sample will lie one standard deviation from the mean, approximately 95% within 2 standard deviations from the mean, and around 99.7% within 3 standard deviations:
This knowledge can also be used to check the mean and standard deviation were appropriate summary statistics, even if we have no other information.
Exercise 4
How many respondents had both weekly rent and mortgage payments given? What are the potential reasons for this?
Combine the weekly rent and mortgage variables into a single weekly payment variable.
Hint
Use all available resources, including help files and cheatsheets if you are struggling to find a function to do this.
Create a summary table containing the mean, median, standard deviation, and the upper and lower quartiles of the weekly payment (rent and mortgage combined) for each region. What, if anything, can you infer about the distribution of this variable based on the table?